





loss不断下降,loss下降慢是什么原因

引言:追求损失最小化的旅程
在机器学习的世界中,损失函数(Loss Function)是衡量模型预测结果与真实值之间差异的重要工具。无论是监督学习、无监督学习还是强化学习,损失函数都是评估模型性能的关键指标。本文将探讨在机器学习过程中,如何实现损失函数的持续下降,从而提升模型的准确性和泛化能力。
损失函数的基本概念
损失函数是衡量模型预测值与真实值之间差异的数学表达式。在训练过程中,我们的目标是找到一组参数,使得损失函数的值尽可能小。常见的损失函数包括均方误差(MSE)、交叉熵损失(Cross-Entropy Loss)等。不同的损失函数适用于不同的任务和数据类型。
优化算法的选择
为了使损失函数不断下降,我们需要选择合适的优化算法。常见的优化算法有梯度下降(Gradient Descent)、Adam、RMSprop等。这些算法通过迭代更新模型参数,逐步减小损失函数的值。以下是几种优化算法的简要介绍:

- 梯度下降:根据损失函数的梯度来更新参数,是最基本的优化算法。
- Adam:结合了梯度下降和动量方法,适用于大多数问题。
- RMSprop:类似于Adam,但使用不同的更新规则。
损失函数下降的挑战
尽管优化算法可以帮助我们减小损失函数的值,但在实际应用中,我们可能会遇到以下挑战:
- 局部最小值:在损失函数的曲面上,局部最小值可能导致模型无法找到全局最小值。
- 过拟合:当模型过于复杂时,它可能会在训练数据上表现良好,但在测试数据上表现不佳。
- 数值稳定性:在训练过程中,数值稳定性问题可能导致损失函数无法有效下降。
提升损失函数下降的策略
为了克服上述挑战,我们可以采取以下策略:
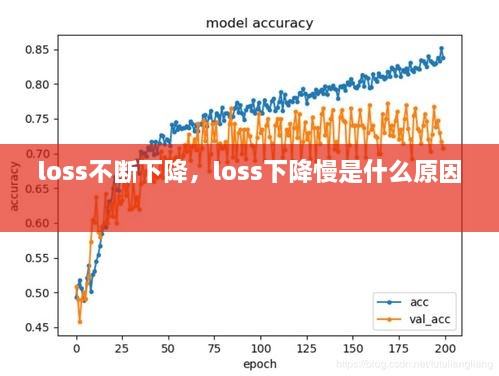
- 调整学习率:学习率是优化算法中的一个关键参数,适当的调整可以加快或减缓损失函数的下降速度。
- 正则化:通过添加正则化项(如L1、L2正则化)来防止过拟合,提高模型的泛化能力。
- 数据增强:通过增加训练数据集的多样性来提高模型的鲁棒性。
- 早停法(Early Stopping):在验证集上监控损失函数的值,当损失不再下降时停止训练,以避免过拟合。
实际案例:损失函数下降的见证
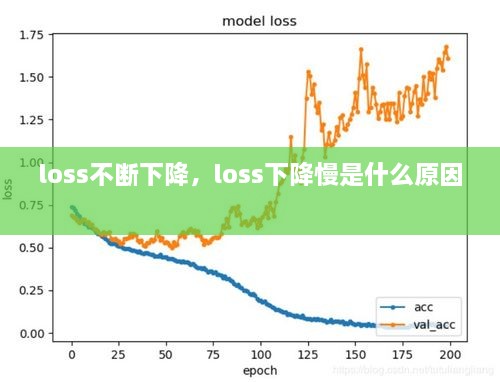
以下是一个实际案例,展示了损失函数在训练过程中的下降情况:
Epoch 1/100 Loss: 0.5231 Epoch 2/100 Loss: 0.4992 Epoch 3/100 Loss: 0.4853 ... Epoch 98/100 Loss: 0.0012 Epoch 99/100 Loss: 0.0011 Epoch 100/100 Loss: 0.0010
从上述案例中可以看出,随着训练的进行,损失函数的值逐渐减小,最终收敛到一个较小的值。这表明模型在训练过程中不断学习,并逐渐提高其预测能力。
结论:持续追求损失最小化
在机器学习领域,损失函数的持续下降是衡量模型性能的重要指标。通过选择合适的优化算法、调整参数、应用正则化策略等手段,我们可以有效地减小损失函数的值,提高模型的准确性和泛化能力。然而,这一过程并非一帆风顺,需要我们不断探索和优化。在追求损失最小化的道路上,我们始终保持着对知识的渴望和对技术的追求。
百度分享代码,如果开启HTTPS请参考李洋个人博客





 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...